Ember Data for the Curious
So a topic that often comes up for folks new to Ember is Ember Data. There's a whole bunch of fear around the topic and Ember Data (ED) is frequently maligned.
I hope that I can provide some insight into the way ED works, particularly when you have an API that may not match the JSON-API spec.
Why do people hate Ember Data?
There's no point pretending, ED has gotten a lot of bad press. It's an ambitious project that has suffered some challenges up to this point.
Yeah, but why?
In the early days (think 2011), the project started out with the idea of solving the connection between your application and a persistence layer. As with many parts of Ember, the early days had a LOT of churn. It seemed like every tiny update broke the world or required a huge re-engineering effort. Whilst this was immensely frustrating, the whole project was in beta and (in my opinion) had license to experiment with the approaches that would work. As the community experimented with ED it became clear that parts of the initial approach were not going to work long term and that the problem was really quite complex. A specific ED sub team was formed and thing have gotten way better since then.
Another thing that fell out of the process was the creation of a publicly developed specification for the structure of JSON payloads and their associated API. This was also a huge piece of work, but worth the effort I think.
JSON-API, why do I care?
Let's start with a few questions. You're building a JSON based API and need to decide how to structure your data :-
- camelCase, train-case or snake_case?
- Root keys naming objects or just objects?
- Object types defined by key name or a property of objects?
- Relationships, side-loaded, embedded, separate API call?
Now a lot of these decisions are seemingly trivial, but can have a big impact on the flexibility of your approach in the long term.
The JSON-API spec gives very specific guidance on how your data should be structured and provides for a great deal of flexibility. If you choose to use the spec, you may not need to do the heavy lifting, because there are libraries for many languages out there.
If you use JSON-API, you are pretty much good to go with ED, so go make awesome things!
I already have an API and I don't want to change.
All this talk of JSON-API is the place where many folks new to Ember balk and say, "stuff it, I can't be bothered". That's unfortunate, because there are other options.
If you are coming from the Rails world and have been using ActiveModelSerializers, well there's an ED adapter for that.
If you are coming from another background / perspective there are a ton of other ED adapters. Take a look and see if there's something that solves your use case there.
I am a special snowflake and require extreme customisation
Well, you're in luck here! ED is structured such that you can customise most anything. Now, I'm gonna be clear here, if you're doing this there's gonna be some pain and you'll have to be prepared to dive deeply into the docs and probably the source code for ED. That's the problem when you do your own thing.
Caveats aside, let's dig in.
The structure of Ember Data
First, let's try to define what the different parts of Ember Data are.
The store
The store is a container for information that has already been fetched from your persistence layer, but also acts as the 'coordinator' for requests for data. The contents can be inspected from the Ember Inspector.
The store is a Service and is available by default in Routes and Controllers.
The adapter(s)
Adapters define the way in which requests are sent to the persistence layer. It defines a number of methods which can be overridden to customise the process.
Generally there will be an ApplicationAdapter which is used as the base 'class' from which any other adapters can be extended. You can have an adapter for every single model in your application if you choose. They should be named to match the model, e.g. a BigWidget model would have a BigWidgetAdapter noting that this is only necessary if you want to customise it. There is a bit more information about basic adapter customisation here, though it doesn't cover more advanced tweaks (like custom URLs).
The serializer(s)
Serializers define how payloads should be converted between the persistence layer's representation to that consumed by ED. Think of it as a universal translator or a Babelfish! There's a ton of information on how to customize serializers here, so I'll not go into too much detail here.
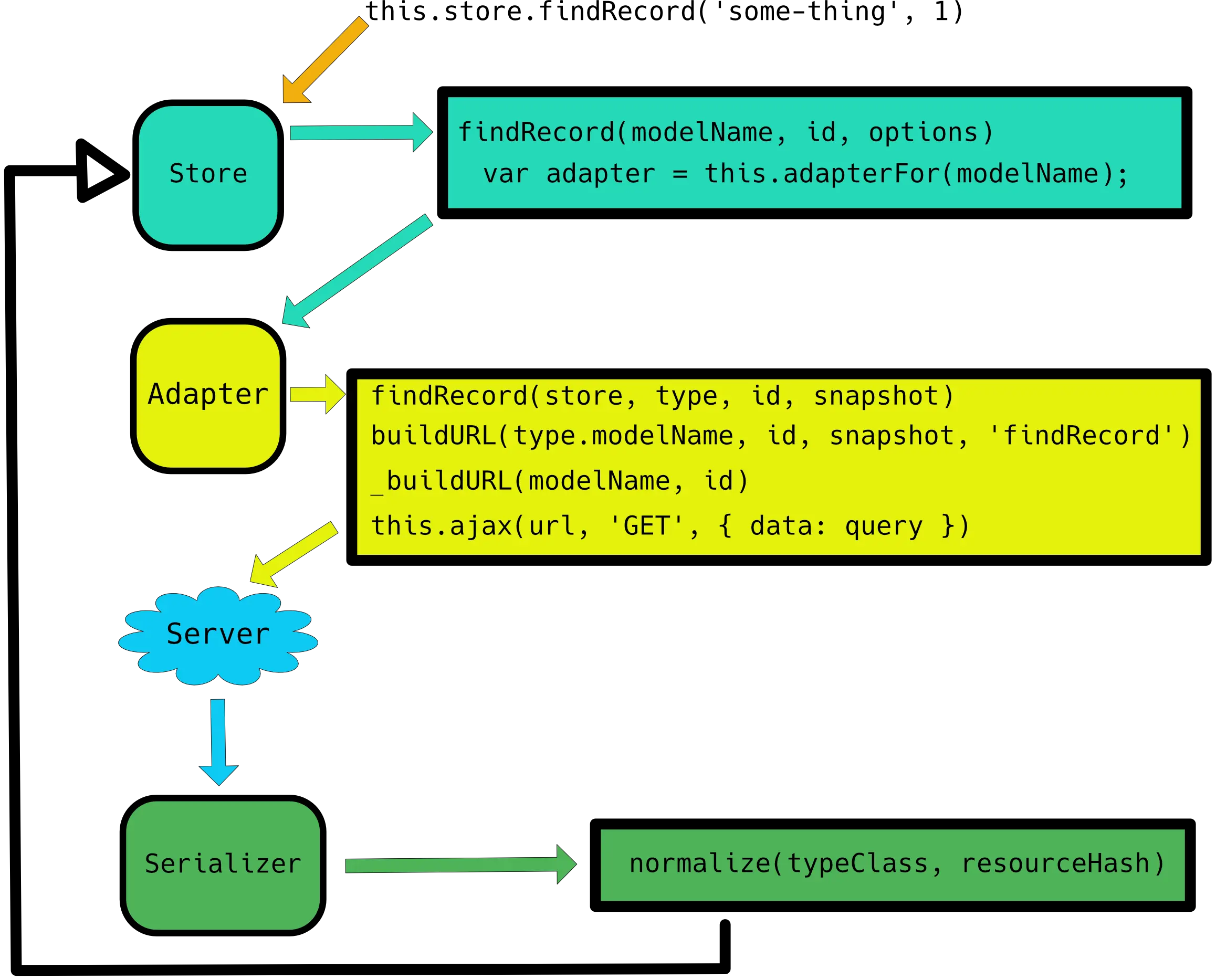
A visual step through
If we want to find a single record, ED provides the findRecord method. It expects the name of a model and an ID. This information.
The store will check for the presence of the record in the store. If the record is found, another property is checked shouldReloadRecord (default: false), if this returns true, the data will be requested from the persistence layer even if it is present in the cache.
Another property is also checked shouldBackgroundReloadRecord (default: true), this decides whether to return the cached item whilst making a request to the persistence layer, which will then be resolved later.
Background reload is useful when you want to ensure you are checking for updated versions without disadvantaging the user. If your user is working on things that are scoped only to them (i.e. no other user can changed the data), it may not be necessary to reload records once they've been retrieved.
In the circumstance that we are to reload a record or one is not present in the cache, the adapter is looked up and findRecord called on the adapter. This method takes the store, type, id and a snapshot. The snapshot has a complex use case, which is beyond the scope of this post, but broadly provides a mechanism for comparing existing and requested data.
Next, the buildURL method is called, which mostly does what you would expect, though there are some 'smarts' that deal with how to build the URL for difference cases (e.g. many records vs single, POST requests vs GET). For a full understanding of what happens during buildURL, visit the mixin source.
Finally a request is made to the persistence layer via an AJAX call.
When the request is resolved, it is passed to the serializer which calls normalize, converting the raw data to ED structure. The object is then pushed into the store.
Sure, but HOW do I customize?
Well, the basic flow is to import the base object and overwrite the parts you need to be different.
Let's take an adapter and assume that I want to change the way a URL is build because my system doesn't care about pluralization and (for some reason, uses camelCase). I also want to reduce the number of requests made to my backend, so will only backgroundReload during specific hours.
//filename big_widget_adapter.js
import DS from 'ember-data';
export default DS.RESTAdapter.extend({
openingHours: [10,11,12],
shouldBackgroundReloadRecord (/* store, snapshot */) {
const now = new Date();
return this.get('openingHours').contains(now.getHours());
},
urlForFindRecord(id, modelName, snapshot) {
return `bigWidget/${id}`;
},
urlForFindAll(modelName) {
return 'bigWidget';
}
});
Wrapping up
So we've taken a stroll around Ember Data and I hope you now have the ability to visualize the process and know where to look when you need to make customizations.
I strongly encourage you to take a look through the codebase, it's very well written, documented and tested.